Hi,davdav:
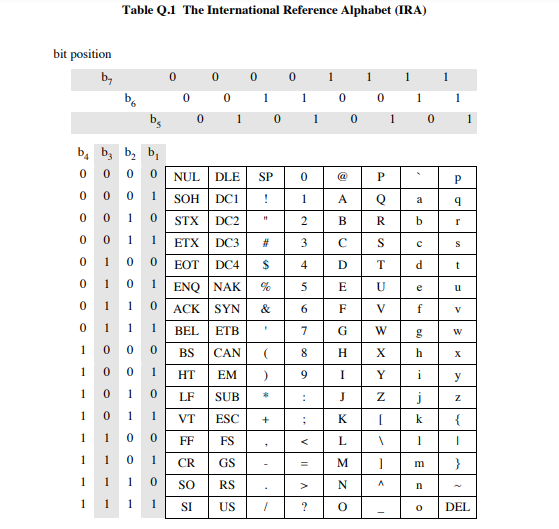
As shown above, the IRA character set does not support the Latin alphabet
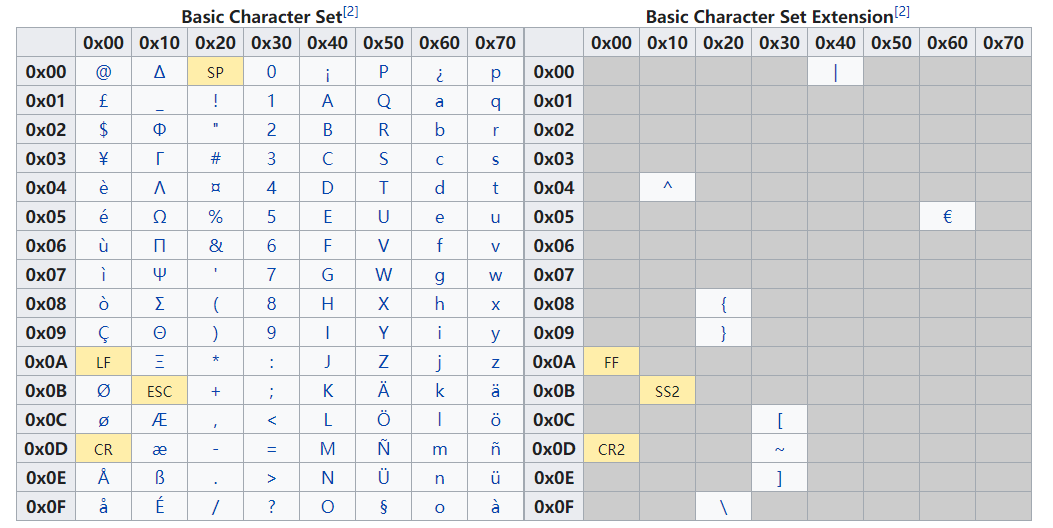
The GSM character set can support part of the Latin alphabet.
In a standard GSM text message, all characters are encoded using 7-bit code units, packed together to fill all bits of octets. So, for example, the 140-octet envelope of an SMS,[3] with no other language indicator but only the standard class prefix, can transport up to (140*8)/7=160, that is 160 GSM 7-bit characters (but note that the ESC code counts for one of them, if characters in the high part of the table are used).
Longer messages may be sent, but will require a continuation prefix and a sequence number on subsequent SMS messages (these prefix bytes and sequence number are counted within the maximum length of the 140-octet payload of the envelope format).
GSM 03.38 - Wikipedia
This encoding allows use of a greater range of characters and languages. UCS-2 can represent the most commonly used Latin and eastern characters at the cost of a greater space expense. Actually, some cell phones (e.g. iPhones) use UTF-16 instead of UCS-2 to display emoticons in short messages.[4]
A single SMS GSM message using this encoding can have at most 70 characters (140 octets).
Note that on many GSM cell phones, there’s no specific preselection of the UCS-2 encoding. The default is to use the 7-bit encoding described above, until one enters a character that is not present in the GSM 7-bit table (for example the lowercase ‘a’ with acute: ‘á’). In that case, the whole message gets reencoded using the UCS-2 encoding, and the maximum length of the message sent in only 1 SMS is immediately reduced to 70 characters, instead of 160. On smartphones the message encoding depends on the SMS application used and its setting as well as on the length of the message. Some smartphones even send longer messages as a multimedia message (MMS).
To avoid unexpected costs for senders that have a subscription for a limited pack of sent SMS, smartphones should display the number of character used and the maximum number of characters in the composed SMS. When a message does exceeds this maximum, the message will be sent as multiple successive SMS containing parts of the message (each one containing a sequence number, which also uses a few leading characters in each part); these parts will be reassembled later by the recipient.
Some GSM smartphones will alert the user about the number of SMS messages needed to send the message, when it requires more than one.